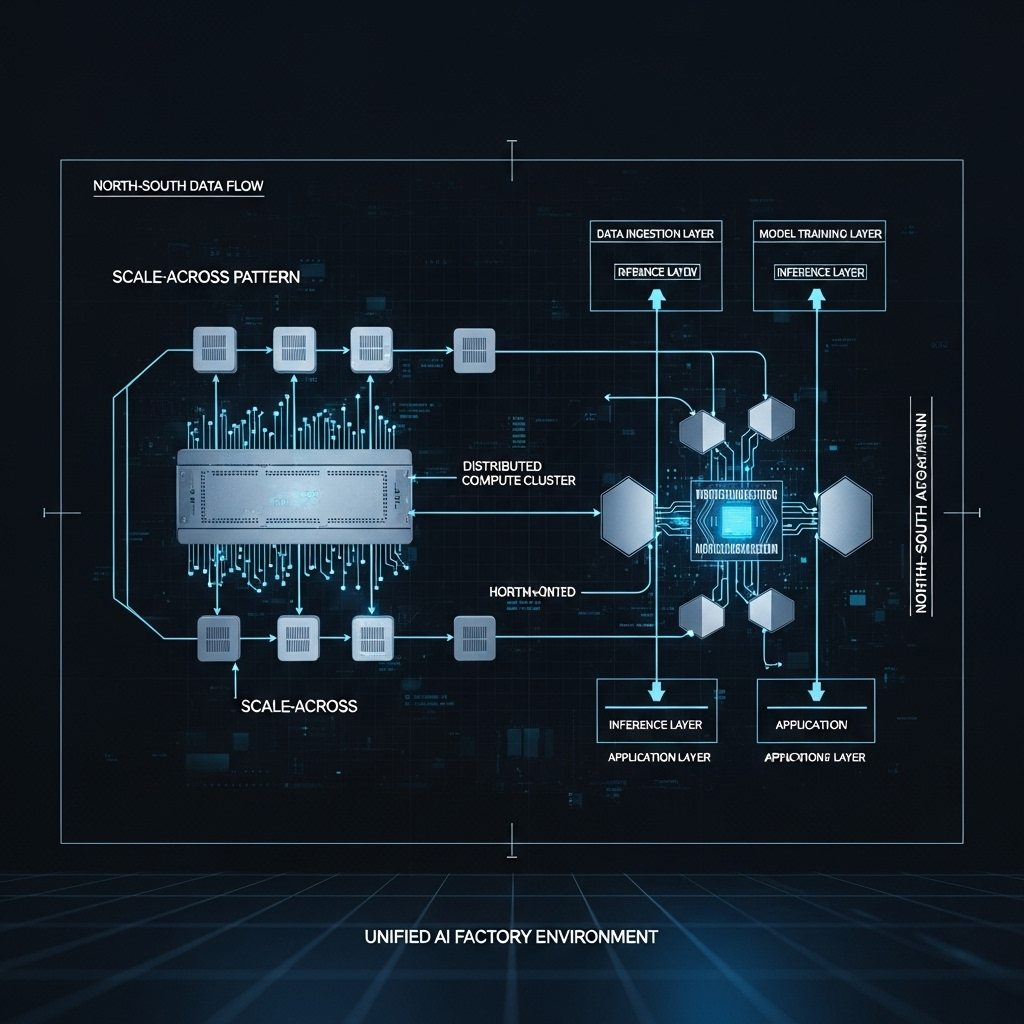
AI performance is no longer just about the GPU; it’s increasingly limited by the network. Recognizing this, NVIDIA has released a developer playbook that formalizes a new reality for AI infrastructure. The guidance details specific operating patterns: scale-across networking to unite multiple sites into a single AI factory, north–south designs to speed up enterprise data flows, and a low-latency stack for jitter-sensitive industries. This creates a pragmatic framework that directly connects network topology to specific AI workloads and performance goals.
Why Network Architecture Now Defines AI Performance
As AI models grow in size and complexity, architects face three dominant constraints: the physical distance between data centers, the need for memory-bandwidth locality, and the demand for low end-user latency. NVIDIA’s guidance argues that these are first-class network design problems, not afterthoughts to GPU cluster construction. By defining adaptable patterns for cloud, on-premises, or hybrid environments, the focus shifts to planning the network fabric in tandem with compute and storage. Success is no longer measured just in FLOPs, but in practical outcomes like tokens per second and predictable tail latency.
A Blueprint for AI Fabrics: Three Core Patterns
NVIDIA’s framework is built on three distinct yet complementary networking patterns, each designed to address a specific class of AI workload.
Scale-Across Networking: Unifying Distributed Data Centers
NVIDIA introduces scale-across as a third dimension of scaling, distinct from traditional scale-up (bigger servers) and scale-out (more servers). The goal is to link geographically dispersed data centers so they function as a single, cohesive AI factory for massive training jobs or high-volume inference. The key is to maintain high effective bandwidth and performance isolation between sites, ensuring that collective operations and parameter synchronization remain stable despite the distance, as detailed in NVIDIA’s scale-across explainer. This approach is ideal for distributed training that exceeds the limits of a single site, unifying compute resources while providing the necessary bandwidth isolation for collective operations.
North-South Networking: Accelerating Enterprise Data
For many enterprises, the real bottleneck is the path data takes from users and data lakes into GPU clusters and back out again. NVIDIA’s north–south pattern concentrates on this “frontend” fabric, which covers everything from data ingress to storage access. The focus is on achieving low jitter and predictable throughput for workloads like enterprise inference and Retrieval-Augmented Generation (RAG). The recommendations center on using hardware offloads like BlueField DPUs and RDMA over Converged Ethernet (RoCE) to reduce CPU overhead and accelerate time-to-first-token for inference, as outlined in their guide to north-south networks. For teams seeing unpredictable latency spikes in production, this pattern offers a clear path to improvement by treating the frontend fabric as a critical subsystem with its own performance targets.
Low-Latency Stacks: Meeting Microsecond Demands
In fields like financial services, AI-driven applications demand microsecond-level response times with almost no variability. For these jitter-sensitive workflows, NVIDIA offers a specialized toolkit combining Rivermax, an optimized IP streaming SDK, with NEIO FastSocket, a kernel-bypass middleware. This stack is engineered to dramatically shrink network overhead, sustain high packet rates, and stabilize timing for real-time inference, algorithmic trading, and market data pipelines. As detailed in NVIDIA’s low-latency networking blog, it leverages NVIDIA adapters for direct data movement that minimizes CPU involvement. This pattern shows that as AI’s footprint expands, architects need a diverse toolkit to meet a wide range of Service Level Objectives (SLOs).
What This Means for the AI Ecosystem
These networking patterns have distinct implications for different players in the AI landscape. Cloud builders can use scale-across principles to make multi-region AI factories behave more predictably, with schedulers that can reason about inter-site fabric conditions. For enterprises, the north-south guidance provides a way to achieve measurable latency and throughput gains by offloading packet processing and instrumenting the frontend fabric—often without refactoring the AI models themselves.
For vendors, NVIDIA’s framework translates workload requirements into concrete feature sets for switches, DPUs, and software. This aligns with the broader industry trend of elevating the network fabric to the role of a co-processor, a concept explored in our analysis of the hardening of the AI infrastructure stack. Of course, risks remain. These patterns are not one-size-fits-all, and fast-moving model architectures can alter traffic profiles unexpectedly. However, these challenges are reasons to build robust observability into the network, not to delay network-first planning.
The Future is Fabric-Aware
NVIDIA’s guidance signals a durable shift in AI system design: the network is now a primary lever for performance. We can expect to see network topology, protocol development, and hardware offload evolve in lockstep with AI model behavior, especially as agents and long-context inference create new traffic patterns. In practice, design reviews for AI clusters will treat fabric telemetry, queue management, and DPU offload as critical components, just as important as HBM capacity and GPU counts.
For architects, the path forward is to define performance SLOs at the workload level and then choose the networking patterns that can meet them reliably. Over the next 6 to 18 months, this trend will likely translate into concrete adoption patterns.
- Scale-across pilots: Hyperscalers and large cloud operators will begin linking regional sites into unified AI factories for specific training tasks, measuring success by how closely they can maintain single-site performance.
- Standardized north-south designs: DPUs and RoCE-aligned storage will become standard in enterprise AI deployments, delivering measurable improvements in inference latency, especially for RAG pipelines.
- Consolidated low-latency stacks: The Rivermax and FastSocket stack will see growing adoption in finance and at the edge, where microsecond-level jitter directly impacts business outcomes.
Ultimately, networking is becoming the explicit control knob for managing tokens per second and latency. The most successful AI factories will be those designed with that knob front and center.


