
This week, DeepSeek launched a chatbot using a new kind of AI called sparse attention. The big deal? This model can handle much longer conversations and documents—and it does so at half the usual cost. That drop could make ‘big memory’ features standard, not just a splurge. Let’s unpack what changed, who benefits, and what signs show this shift is here for good.
The Short Version
- DeepSeek released a chatbot with sparse attention—cutting long-context AI costs by up to 50%.
- If real-world savings persist, document-heavy chat and memory-driven features will be much cheaper everywhere.
- This could change how consumer apps and APIs are priced—and what they offer as standard.
What Changed
Traditional AI chat models pay a high compute bill when processing long conversations or multi-document uploads. DeepSeek’s experimental chatbot uses sparse attention—a method that focuses AI’s “thinking” only on the most important pieces instead of every single word. This approach was previously tested mainly in controlled labs, but DeepSeek shipped it straight into an app that anyone can use. Now, instead of compute costs ballooning with every extra file or long chat, the model keeps prices in check by picking its battles. The details matter: the real win comes from how the system learns to highlight key information during training, not after the fact. Early public tests suggest the approach works for unpredictable, real-world usage and not just benchmarks. The result? Memory-heavy AI features just got much more affordable to run.
Sparse attention moves from lab demo to daily use, promising cheaper long-context AI for everyone.
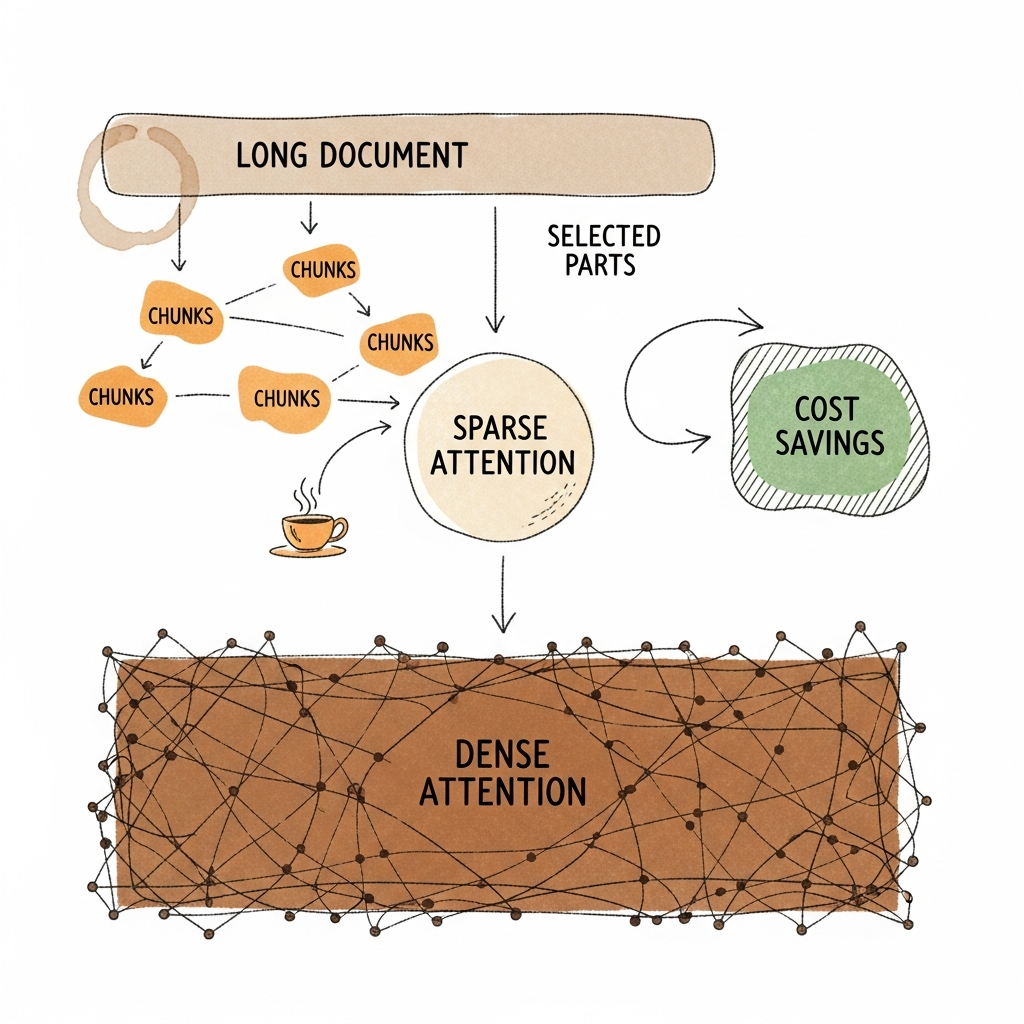
Why You Should Care
Life
You can now chat with AIs about long email threads, big reports, or multiple files—without splitting them into pieces or worrying about cost. This unlocks more meaningful work and less time spent playing prompt Tetris. If you’ve ever wanted to stick your whole project into a chatbot, this is good news.
Longer, richer AI conversations are now possible for everyday users.
Work
For teams, cheaper long-context means you can offer persistent chat history and richer document understanding in customer support, research, or internal tools. Features that used to be ‘premium’ can become default—like having your company’s knowledge base truly searchable by AI.
Teams and apps can make smarter features available without running up big bills.
Wallet
If you pay for AI by the token or by session, your costs may go down as this tech spreads. Developers and buyers should watch vendors—competition will likely spark more generous pricing, larger context windows, and better value without a hike in spend.
Expect more AI for your money, and bigger features at the same price.
What To Watch Next
- Do rival AI vendors launch their own sparse or hybrid attention models?
Confirm if: You see price drops or new features for long-context use from other providers.
Deny if: Incumbent vendors delay or stick with dense attention, keeping costs high for large context windows. - Does DeepSeek’s cost advantage hold in varied, real-world apps—not just benchmarks?
Confirm if: User reviews and developers report stable, low costs for long, messy conversations and big uploads.
Deny if: Reports emerge about hidden quality drops, errors in long chats, or costs creeping up in daily use.
If You’re a Founder/Leader
- Pilot long-context AI features now—test pricing and quality on your actual workloads, not just vendor claims.
- Model how lower costs could let you offer new memory-driven tools or pass savings to your users without extra spend.
Sources
Deep dive: https://vectorforecast.com/deepseek-sparse-attention-cheaper-long-context/
Additional reading: https://techcrunch.com/2025/09/29/deepseek-releases-sparse-attention-model-that-cuts-api-costs-in-half/


